
Abstract
Text-to-Image (T2I) diffusion models have gained popularity recently due to their multipurpose and easy-to-use nature, e.g. image and video generation as well as editing. However, training a diffusion model specifically for 3D scene editing is not straightforward due to the lack of large-scale datasets. To date, editing 3D scenes requires either re-training the model to adapt to various 3D edited scenes or design-specific methods for each special editing type. Furthermore, state-of-the-art (SOTA) methods require multiple synchronized edited images from the same scene to facilitate the scene editing. Due to the current limitations of T2I models, it is very challenging to apply consis- tent editing effects to multiple images, i.e. multi-view inconsistency in editing. This in turn compromises the desired 3D scene editing performance if these images are used. In our work, we propose a novel training-free 3D scene editing technique, FREE-EDITOR, which allows users to edit 3D scenes without further re-training the model during test time. Our proposed method successfully avoids the multi- view style inconsistency issue in SOTA methods with the help of a “single-view editing” scheme. Specifically, we show that editing a particular 3D scene can be performed by only modifying a single view. To this end, we introduce an Edit Transformer that enforces intra-view consistency and inter-view style transfer by utilizing self- and cross- attention, respectively. Since it is no longer required to re-train the model and edit every view in a scene, the editing time, as well as memory resources, are reduced significantly, e.g., the runtime being ∼ 20× faster than SOTA. We have conducted extensive experiments on a wide range of benchmark datasets and achieve diverse editing capabilities with our proposed technique
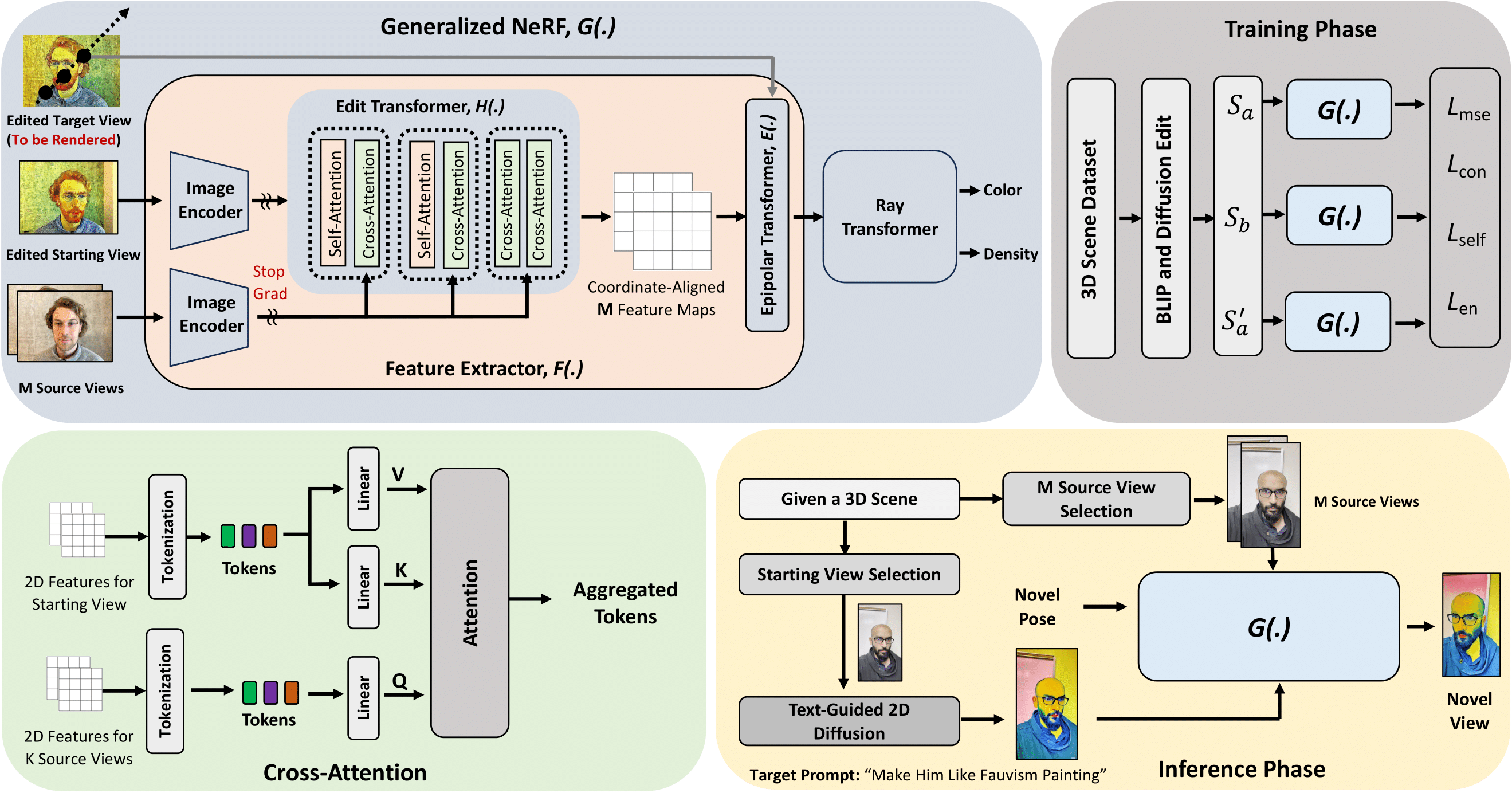
Overview of our proposed method. We train a generalized NeRF (G(.)) that takes a single edited starting view and M source views to render a novel target view. Here, ”Edited Target View” is not the input to the model rather will be rendered and works as the ground truth for the prediction of G(.). In G(.) we employ a special Edit Transformer that utilizes: cross-attention to produce style-informed source feature maps that will be aggregated through an Epipolar Transformer.
Experimental Results
Comparison
We obtain similar performance as compared to other SOTA techniques. To edit a scene, it only takes around 3 minutes as compared to 70 minutes in SOTA.

More text-based 3D editing results. Free-Editor can handle the diverse prompts-based generation quite well.

BibTeX
@misc{karim2023freeeditor,
title={Free-Editor: Zero-shot Text-driven 3D Scene Editing},
author={Nazmul Karim and Umar Khalid and Hasan Iqbal and Jing Hua and Chen Chen},
year={2023},
eprint={2312.13663},
archivePrefix={arXiv},
primaryClass={cs.CV}
}